Most AI workflows get noisier the more you add to them. This one gets cleaner.
How did this come together?
I’ve been thinking about the relationship between deterministic and generative processes for about a year. The question was always the same: where does the machine end and the intelligence begin?
The release of Opus 4.6 showed me there isn’t a capability limit to the latest gen models. Then I learned about Claude Agent Teams and started thinking seriously about orchestration differently. What happens when you stop treating an LLM as a single call or series of calls and start treating it as a team? This opened my eyes to the world of AI research and what labs are actively exploring.
What’s the core idea?
Every problem has two kinds of work inside it: work that should be deterministic, and work that requires intelligence. The engineer’s job is to find the line between them.
Parsing, indexing, structuring, fetching, counting: that’s deterministic. Hand it to code. Reasoning, synthesis, judgment, contradiction: that’s intelligence. Hand it to the model. Get the line wrong and you’re either paying for intelligence where a for-loop would do, or asking code to do something it can’t.
Once the line is drawn, the rest follows: compress the deterministic output into the smallest prompt that preserves the signal, then give each model call only the slice it needs to make its specific decision. Nothing more.
Why does this work?
Signal up, noise down. That applies at every level:
- The human’s prompts scope the problem before the agent sees it
- The deterministic tool compresses the input before the LLM touches it
- The orchestrator map-reduces across the context window so each call sees only what matters
Noise is eliminated progressively. Not filtered after the fact.
What are the steps?
Here’s the process I’ve landed on.
Step 1: Map the problem before you touch the model.
Write three prompts. Not to get answers. To find out where the complexity lives. What’s ambiguous? What has clear boundaries? What requires judgment versus lookup? You’re scoping the problem space, its shape, its edges, and the parts that will fight back.
Step 2: Draw the line between code and cognition.
Fetching a URL, stripping HTML, counting tokens. That’s code. Deciding whether two facts contradict each other. That’s the model. You decide where that line goes. Get it wrong and you’re paying for intelligence where a for-loop would do. Parsing, indexing, and structuring is deterministic. Reasoning, synthesis, and judgment is LLM.
Step 3: Give each call one job and only the context it needs.
Agent A summarizes sources. Agent B extracts key facts. Agent C flags contradictions. None of them see the full picture. The orchestrator does. It map-reduces across the context window so each call gets a compressed, scoped input. Results accumulate.
Step 4: Run it through two filters that don’t trust each other.
A human reviews outputs and corrects where judgment is needed. A second agent, a different model from the one that wrote the report, challenges the first agent’s output, looking for errors, gaps, and unsupported reasoning. Neither alone is sufficient. Together they catch what each misses.
Step 5: Make the system describe itself.
Ask the system to produce a prompt describing its own architecture. If it can’t explain what it’s doing clearly, the design is too complex. The system describes what it is in a form the human can reason about. Compression applied to the system itself.
Step 6: Feed the architecture back in with your corrections.
You read the self-description. You spot what’s wrong. You hand both back to the agent team. Here’s what you are. Here’s what needs to change. Your judgment steers. The agent’s breadth fills in.
Step 7: Stop finding the problems. Start reviewing the problems it finds.
When the system becomes more complicated than you can hold in your head, your role shifts from driver to editor. The flywheel is spinning when you trust the system enough to let it tell you what’s broken.
What does this produce?
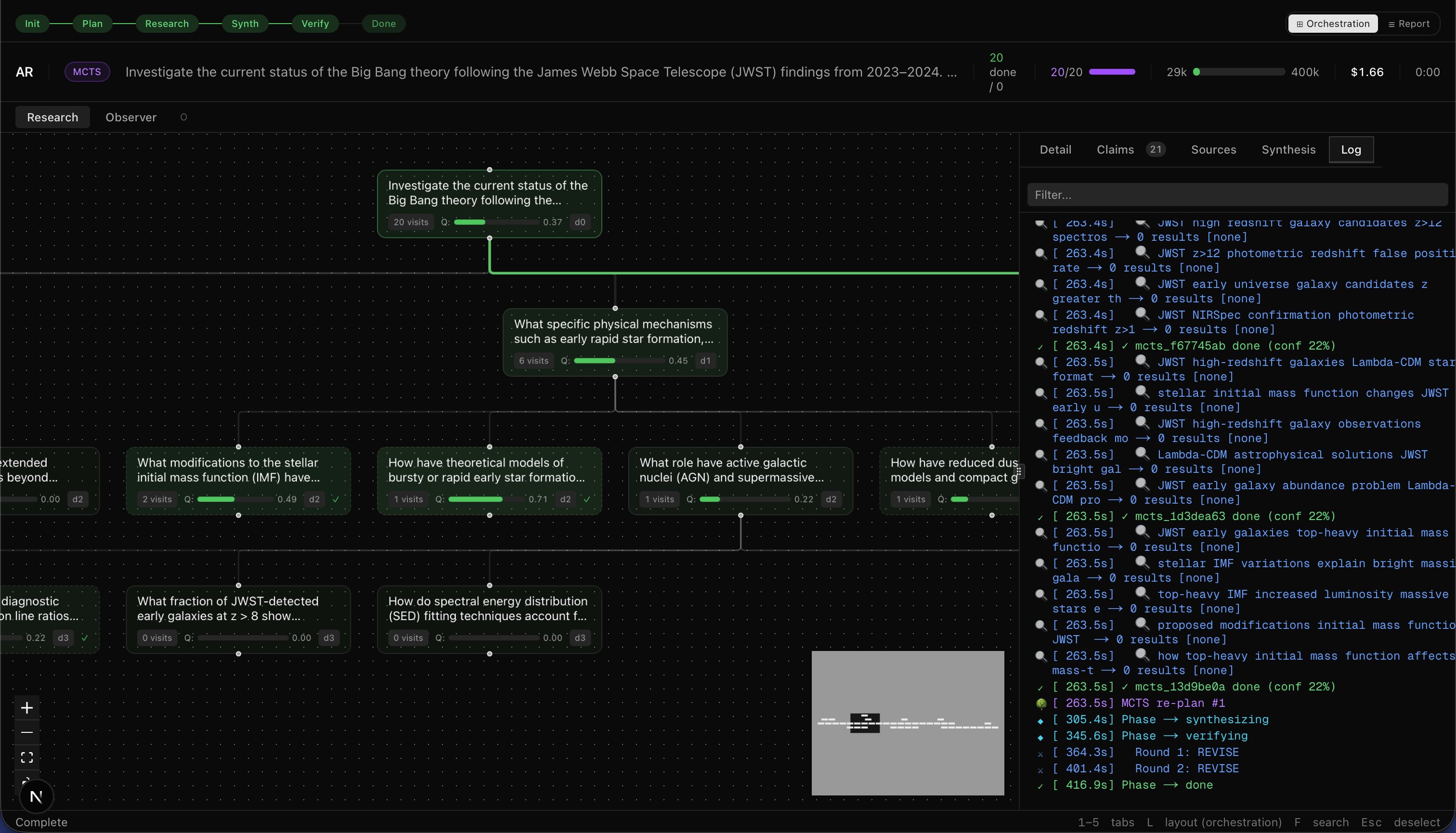
I built a deep research tool using this methodology. My system costs ~$1.50 to run.
The tool takes a question and returns a citation-backed report. I asked it whether JWST had disproven the Big Bang. Here’s part of what came back:
The JWST discoveries of bright, massive galaxies in the early universe have exposed significant tensions with the standard ΛCDM cosmological model’s predictions for early galaxy formation. The available literature frames these as challenges to galaxy formation models… Whether these tensions ultimately require only model adjustments or more fundamental revisions to cosmological theory remains an open and actively investigated question.
Every sentence traces to a source. Claims are tagged with confidence scores. Contradictions between sources are flagged before synthesis. A second model challenges everything the first one wrote. Does this mean it’s correct? No. LLMs are still going to hallucinate. The goal of this project isn’t to eliminate hallucination; it’s to reduce it.
Don’t take the report at face value. It’s not a real research report. The claims table and verification debate at the bottom of the PDF show exactly how it got there.
What’s the rule?
Signal increases. Noise decreases. No output moves forward unchecked. Each cycle compresses further. Each generation is cleaner than the last.
Single-model output is a draft. Reviewed output is a result. The system must know the difference. So must the human.